
StashCache
StashCache is a framework to distribute data across the Open Science Grid. It is designed to help opportunistic users to transfer data without the need for dedicated storage or frameworks of their own, like CMS and ATLAS have deployed. StashCache has several regional caches and a small set of origin servers. Caches have fast network connections, and sizable disk storage to quickly distribute data to the execution hosts in the OSG.
StashCache is named for the Stash filesystem located at the University of Chicago’s OSG-Connect service. It is primarily intended to be used to cache data from the Stash filesystem, though, data origins exist for other experiments.
Components
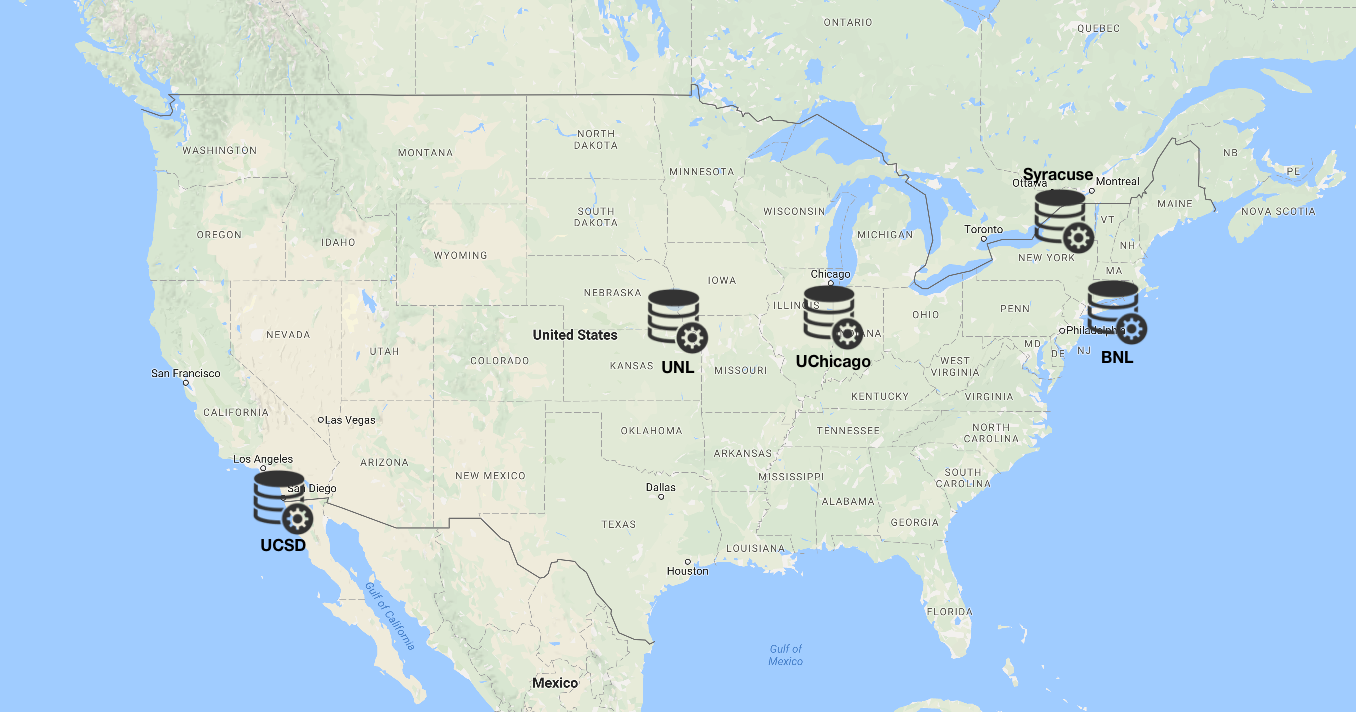
The worker nodes are where the user jobs will run. The transfer tools are used on the worker nodes to download data from StashCache caches. Worker nodes are geographically distributed across the US, and will select the nearest cache based upon a GeoIP database.
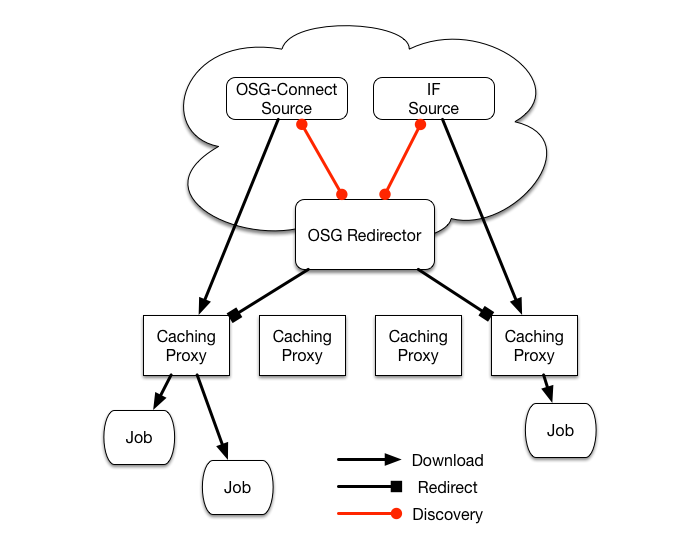
The caches are distributed to computing sites across the U.S. They are are running the XRootD software. The worker nodes connect directly to the regional caches, which in turn download from the Origin servers. The caching proxies discover the data origin by querying the Redirectors. The caching algorithm used is Least Recently Used (LRU). In this algorithm, the cache will only delete cached data when storage space is near capacity, and will delete the least recently used data first.
The origin servers are the primary source of data for the StashCache framework. StashCache was named after the Stash data store at the University of Chicago’s OSG-Connect service, but other origins also utilize the framework. The origin is the initial source of data, but once the data is stored on the Caches, the origin is no longer used. Updates to data on the origin are not reflected in the caches automatically. The caches treat the data from the origin as immutable, and therefore do not check for updates. If a user requires new data to be pulled into the cache, the name or location of the data on the origin must be changed.
Redirectors are used to discover the location of data. They are run only at the Indiana Grid Operations Center (GOC). The redirectors help in the discovery of the origin for data. Only the caching proxies communicate with the redirectors.
Tools to transfer
Two tools exist to download data from StashCache, CVMFS and StashCP. With either of these tools, the first step for users is to copy the data to the Stash filesystem. Once the user has an OSG-Connect account, they may copy their data to the /stash//public directory. Once there, both of the tools can view and download the files.
CVMFS (CERN Virtual Machine File System) is a mountable filesystem that appears to the user as a regular directory. CVMFS provides transparent access for users to data in the Stash filesystem. The namespace, such as the size and name of files, and the data are separate in the Stash CVMFS. CVMFS distributes the namespace information for the Stash filesystem over a series of HTTP Forward Proxies that are separate from the StashCache federation. Data is retrieved through the Stash proxies.
In order to map the Stash filesystem into CVMFS, a process is constantly scanning the Stash filesystem checking for new files. When new files are discovered, they are checksummed and the meta-data is stored in the CVMFS namespace. Since this scanning can take a while for a filesystem the size of Stash, it may take several hours for a file placed in Stash to be available through CVMFS.
Using CVMFS, copying files is as easy as copying files with any other filesystem:
$ cp /cvmfs/stash.osgstorage.org/user/<username>/public/… dest/
CVMFS access also has other features that are beneficial for Stash access. CVMFS will cache files locally so that multiple accesses to the same file on the same node will be very fast. Also, CVMFS can fallback to other nearby caches if the first fails.
StashCP is the second tool that can download data from StashCache. StashCP uses CVMFS above, as well as falling back to the caching proxies and eventually the origin. The order of operations that StashCP performs:
- Check for the file in CVMFS mount under /cvmfs/stash.osgstorage.org/…
- If CVMFS copy fails, connect directly to the nearest proxy and attempt to download the file.
- If the proxy fails, then connect directly to the origin server.
Since StashCP doesn’t rely on the CVMFS mount only, files are immediately available to transfer with StashCP.
StashCP is distributed with OSG-Connect’s module system. Using StashCP is nearly as simple as using the cp command:
$ module load stashcp
$ stashcp /user/<username>/public/… dest/
Conclusions
The StashCache framework is very useful for downloading data to execution hosts across the OSG. It was designed to help opportunistic users to transfer data without the need for dedicated storage or frameworks of their own, like CMS and ATLAS have deployed.
StashCache has been used to transfer over 3 PB of data this year. Check out some of the papers written about using StashCache:
- Derek Weitzel, Brian Bockelman, Duncan A. Brown, Peter Couvares, and Frank Wu ̈rthwein, Edgar Fajardo Hernandez. 2017. Data Access for LIGO on the OSG. In Proceedings of PEARC17, New Orleans, LA, USA, July 09-13, 2017, 6 pages. DOI: 10.1145/3093338.3093363 Online
- Derek Weitzel, Brian Bockelman, Dave Dykstra, Jakob Blomer, and René Meusel, 2017. Accessing Data Federations with CVMFS. In Journal of Physics - Conference Series. Online