
The HPC cluster as a reflection of values
Yesterday while I was cooking dinner, I happened to re-watch Bryan Cantrill’s talk on “Platform as a Reflection of Values“. (I watch a lot tech talks while cooking or baking — I often have trouble focusing on a video unless I’m doing something with my hands, but if I know a recipe well I can often make it on autopilot.)
If you haven’t watched this talk before, I encourage checking it out. Cantrill gave it in part to talk about why the node.js community and Joyent didn’t work well together, but I thought he had some good insights into how values get built into a technical artifact itself, as well as how the community around those artifacts will prioritize certain values.
While I was watching the talk (and chopping some vegetables), I started thinking about what values are most important in the “HPC cluster platform”.
Technical values
This slide from the talk shows some examples of what Cantrill thinks of as platform values:
A key point from the talk is that all of these are good things! Ideally you want to have all of these things when you build a new platform, whether that’s a programming language, a cloud platform, or whatever. But any given platform will choose to prioritize some set of values over others. You want them all, but when they come into tension, which ones will win?
One example that Cantrill gives in the talk is the original Unix out of Bell Labs, which prioritized simplicity, composability, and portability. Certainly Unix wanted other features, like performance and maintainability, but if forced into a choice like performance vs simplicity, it would generally choose simplicity. Similarly, he talked about how JavaScript and node.js are built around values like approachability, expressiveness, and velocity, and how that contrasted with values like robustness and debuggability that Joyent valued as a cloud provider.
The HPC cluster platform
When I saw “HPC cluster platform”, I’m loosely talking about the collection of hardware and software that is most often used to build high-performance computing clusters for workloads like scientific research or machine learning training.
This generic platform consists of a large collection of identical compute nodes, orchestrated by a batch scheduler like Slurm or PBS, and with one or more “login nodes” serving as a front-end where users SSH in to prepare and run jobs on the cluster. For multi-node jobs and high-speed storage access, the compute nodes are connected by a very high-speed network, like 100Gb Ethernet or InfiniBand, which needs specific libraries to use effectively. Users on the cluster have access to command-line editors and development tools like compilers and scientific libraries, but mostly interact with the platform in a purely command line environment.
See also, this really ugly Google Draw diagram:
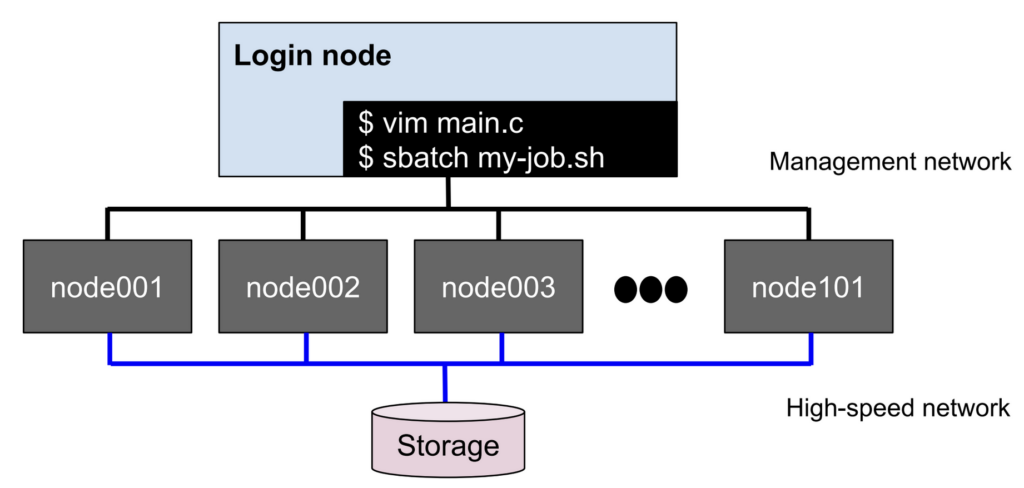
What values does this platform prioritize? In general, I tend to think that HPC platforms prioritize performance, portability, and approachability.
Performance: This might seem obvious given the name “HPC”, but it’s worth thinking a little more about. When faced with a choice between performance and some other value, HPC clusters almost always choose performance.
Performance is generally performance above cost, with most clusters using expensive compute and networking hardware. It’s prioritized over observability (“measurability” on Cantrill’s slide?), with most HPC clusters I’m aware of disabling most active monitoring features if they have a performance cost. It’s even prioritized above security, often turning off security features if they lead to lower performance or even measurable performance variability.
Portability: Mindful of the difficulty in writing high-performance, correct scientific code, the HPC platform works reasonably hard to maintain portability to new hardware and software over time.
A lot of this is due to a robust ecosystem of libraries and middleware. Most applications that scale across multiple nodes still use MPI; code doing linear algebra still depends on long-lived libraries like LAPACK and BLAS; and platform tools like the scheduler tend to be remarkably stable over time. New hardware features are often abstracted by middleware, especially at the networking level where support is built into your MPI library of choice.
This story isn’t perfect — applications usually need recompilation on a new cluster, and still often need major changes to take advantages of new features. That’s why I chose “portability” instead of “compatibility”. But as a cluster admin, I’ve worked with many researchers who have maintained the same app on many different clusters for 10, 20, or even 30 years, which is a pretty impressive portability story.
Approachability: This one may be controversial! The average HPC cluster can seem pretty arcane, especially for someone new to the platform. But I do think that HPC prioritizes a particular kind of approachability, which is that it is designed to onboard scientific researchers who are not themselves expert developers.
A new user onboarding to a research HPC cluster frequently needs to understand three main tools:
- The Linux shell: Most HPC cluster environments are entirely command-line oriented (though Open OnDemand is helping change this!). You log in with SSH; edit using nano, vim, or emacs; and interact with the system entirely using a shell.
- The cluster scheduler: When you have your application ready to go, you submit your job to a queue using a cluster scheduler like Slurm and wait for it to complete. Cluster schedulers have a lot of moving parts and a user can often find endless knobs to tune, but it’s easy to get started with just a few commands. (And interestingly, almost all HPC cluster schedulers define their jobs as… shell scripts! You’re back to needing to know the shell. Annoying, sure, but at least it ain’t YAML!)
- Environment modules: This tool allows the cluster admins to provide a large library of libraries and tools, with specific versions, such that a cluster user just needs to type “module load openmpi/3”. While the tool munges the shell environment variables as needed to set up PATH, LD_LIBRARY_PATH, etc just so.
Now if this doesn’t sound like a robust software engineering environment… it isn’t! There are endless things that can go wrong, especially with environment modules interacting with the user’s own shell rc files and who knows what else. And there’s very little in this environment to encourage best practices like linting, pinned library versions, or even version control at all!
But this environment is approachable… if you’re a graduate student in a field like physics or biology, running an existing application or writing your own simulation or data processing code. But who never got to take a class on software engineering, and where the code itself is not a first class deliverable. The deliverable is the published paper.
But what about all those other values?
They’re still important! But the point of this exercise is to think about which values are will “win” when they come into tension. And I do think that, if you look at HPC clusters in general, this is the set of values that will win.
Availability is important, but not if that work costs us (much) performance. Velocity is great, but we’ll de-prioritize it in the name of workload portability. Security is essential — but we don’t want to make it harder to onboard new grad students…
You cluster is not the generic platform (and neither is mine)
A last point I want to make is that there’s actually no such thing as the “generic HPC cluster platform”. Each individual cluster, at a university or company or government lab, is often configured in a unique way based on the hardware, performance goals, and whims of the person setting it up.
Because of this, each individual HPC cluster may prioritize different values. A cluster at a national lab may choose security at the expense of approachability; or a different cluster may choose to sacrifice portability in the name of velocity if they’re developing on a new hardware or software system.
(Also, the systems I build as part of my day job also make very different choices than the “generic” cluster would. To a first approximation, I think I’d say we choose performance/debuggability/portability/security… but we also make different choices depending on what we’re building!)
But I still think that performance, portability, and approachability represent the most common platform values I’ve seen in the HPC field as a whole. And I think the tools and practices we use bias towards those values.
However… all of that is what I thought about while making dinner! If you think a different set of values makes more sense, feel free to send me an email and let me know. 