I’m back again and revisiting the Turing Pi V1 board. This time the focus isn’t on software, but rather cooling. In my previous write-up Pi in the sky? A compute cluster in mini ITX form factor, I used a USB fan I had at hand to keep the temperature of the compute modules in check during the Linpack runs. Although the fan was a seriously sketchy one, it did the job, and prevented throttling of the compute modules under high load, albeit with much noise. Clearly not content with this mediocre setup I pondered what other solutions I could quickly come up with.
Looking in my electronics spare parts bin, I came across 2 spare Noctua 40x40x20mm fans, part number NF-A4x20 PWM. I found that these fans fit well on the Turing Pi board perpendicular to the compute modules. I measured that for full cooling coverage of the compute modules I’d need 4 such fans, side by side. However before investing in two more fans, I needed to confirm that they had enough oomph (yes that’s a technical term) to keep things cool.
So my plan was to first test two fans cooling half of the modules. However, to test these fans out, I first needed to get a hold of some USB to 3/4-pin fan power adapter cables. Once I had these adapters, I used a thick elastic band to bind the 2 fans together, and connected them to the USB for power using the adapters and give them a whirl - pun intended. Of course I fell back on Linpack to get the compute modules busy.
The results were promising enough that I immediately ordered two more fans and adapters to complete the setup which is shown in the photo below. A thick elastic band was used again to fasten the remaining 2 fans together. Of course, the setup will be made more robust to ensure that fans will stay in place. And I’ll do a bit of work on cable management.

Totally chill
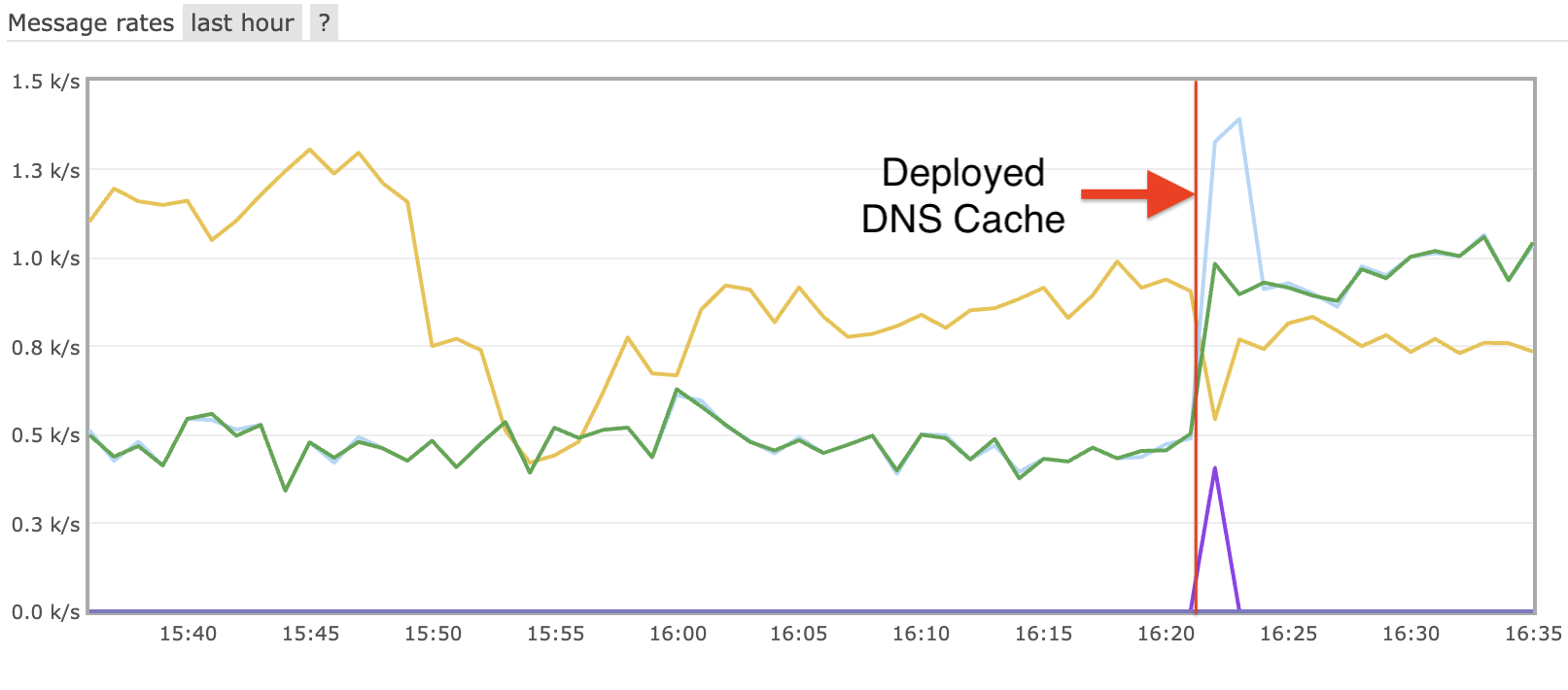
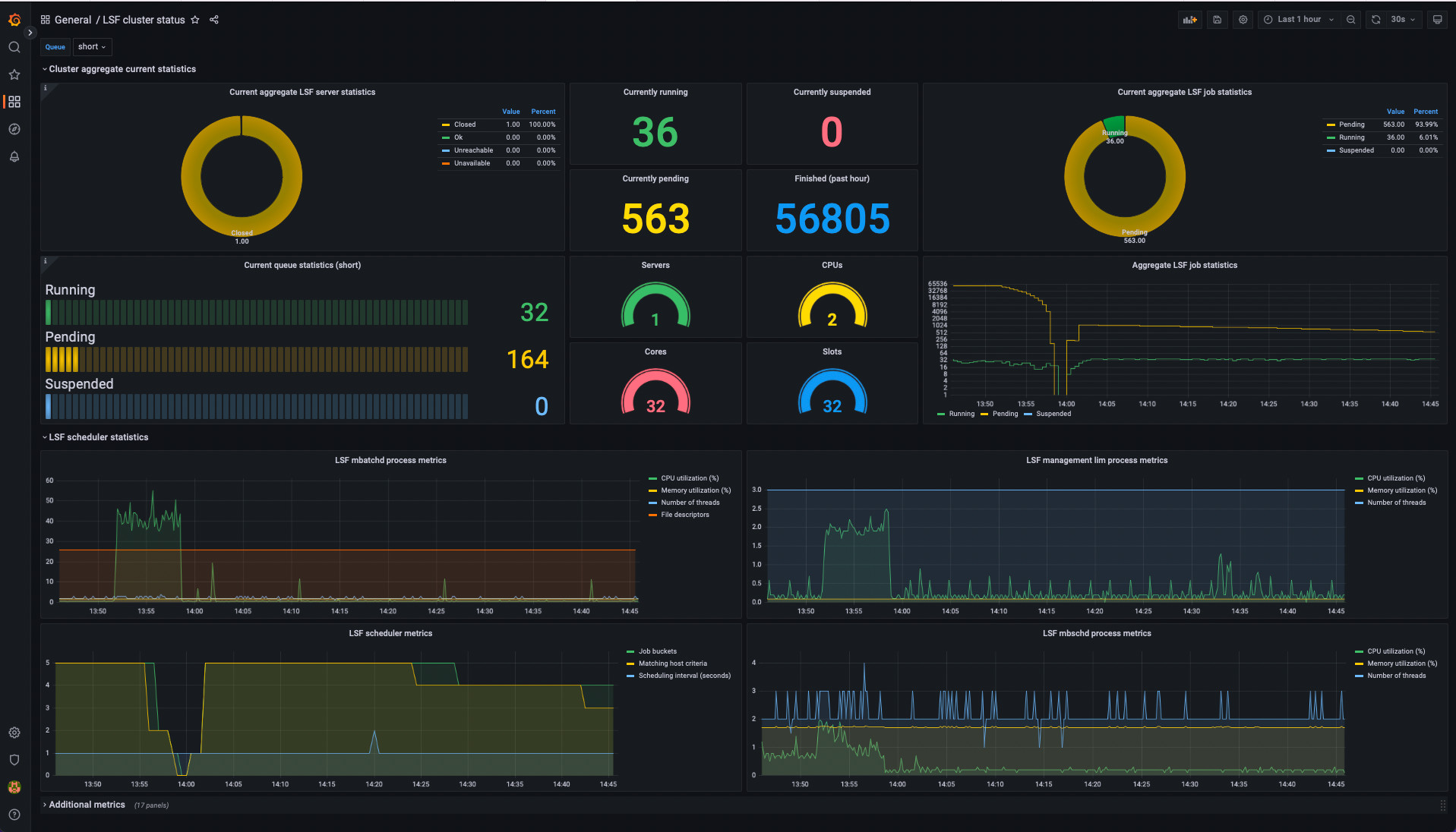
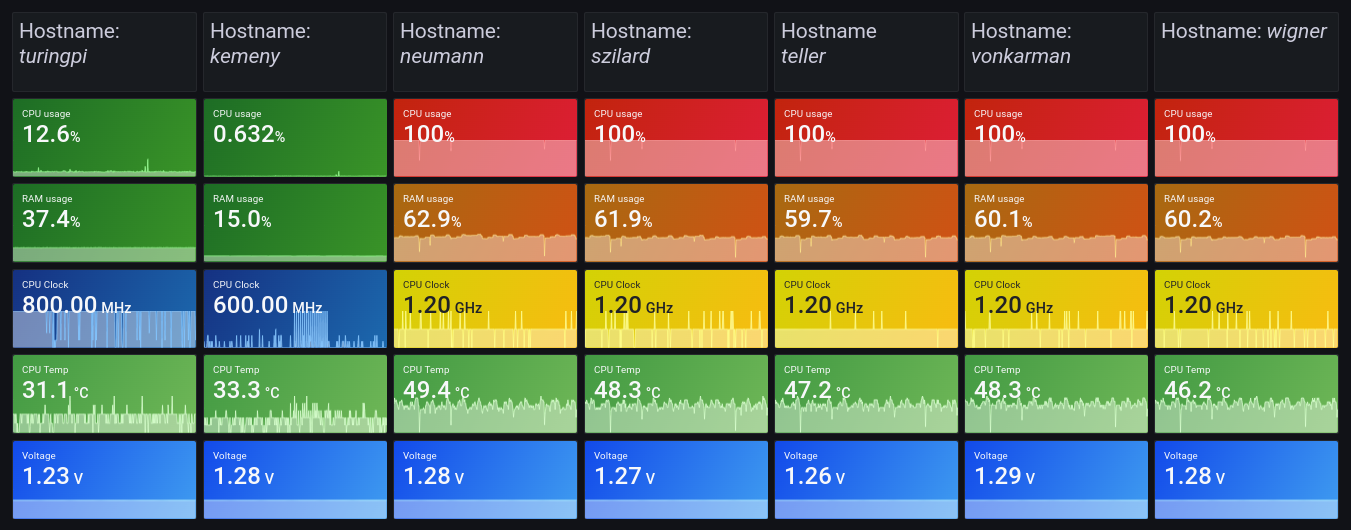
The view of the dashboard (see below) speaks for itself. Under heavy load running Linpack, the compute modules don’t exceed 50C. This is about 10 degrees cooler than what I saw with that USB desk fan. So I’d consider that a result. Plus the Noctua fans are so much quieter and will be much more durable in the long run.
Conclusion
So where does the title of my blog come from? It’s inspired by the slogan “6 turning and 4 burning” of the B-36 Peacemaker strategic bomber! You can see the B-36 in all it’s glory in this short excerpt from the 1955 film Strategic Air Command starring Jimmy Stewart. You could say I have eclectic taste in films. Plus the B-36 has always fascinated me with it’s combination of jet and piston engines. As for this blog, 4 turning obviously refers to the 4 Noctua fans turning. And 7 chilling refers to the 7 CM3 modules that now keep their cool under pressure. With a more suitable cooling solution in place, especially as the warmer days arrive, I can now refocus my attention to the software side of things. And as always, stay cool!
]]>